ON-THE-FLY 实时生成!Wan-AI 万相/ Wan2.1 Video Model (multi-specs) - CausVid&Comfy&Kijai - workflow included
2.6M
2.6K
13.0K
#Base Model
#Video
#basemodel
#dit
...View More
All in One, Wan for All
We are excited to introduce our latest model to our talented community creators:
Wan2.1-VACE, All-in-One Video Creation and Editing model.
Model size:1.3B, 14BLicense:Apache-2.0
If we are in Wan Day, what will it be like? 如果我们在万相世界,会是什么样子?
模型支持两种文本到视频模型(1.3B 和 14B)和两种分辨率(480P 和 720P)。
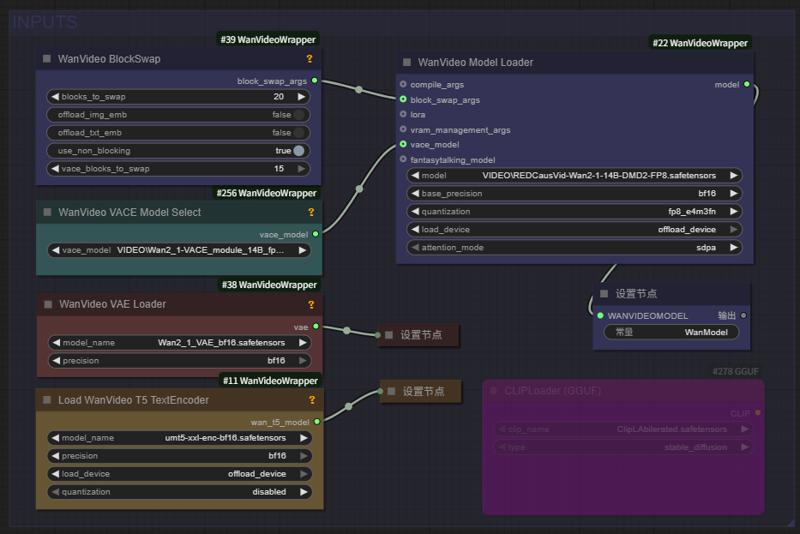
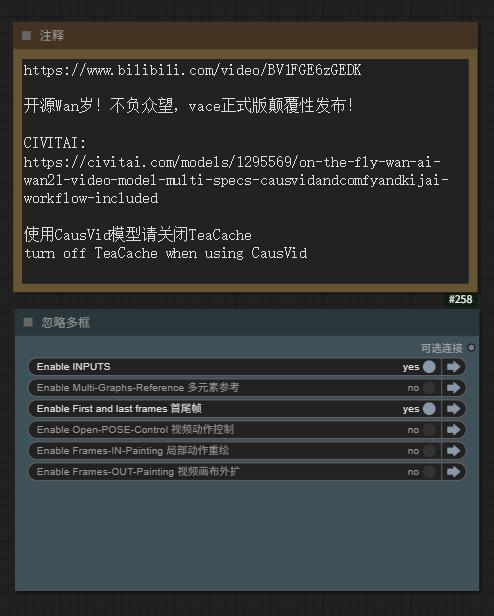
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
VACE is an all-in-one model designed for video creation and editing. It encompasses various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing users to compose these tasks freely. This functionality enables users to explore diverse possibilities and streamlines their workflows effectively, offering a range of capabilities, such as Move-Anything, Swap-Anything, Reference-Anything, Expand-Anything, Animate-Anything, and more.
KJ give us a universal CausVid LoRA in rank32 for Any 14B WAN model,
EVEN including FT models and I2V model!
Although this may not have been CausVid's initial intention, by flexibly adjusting the LoRA parameters (0.3~0.5), we have achieved unprecedented availability on home grade graphics cards!
KJ-Godlike also provides a 1.3B bidirectional inference version of LoRA export file
本页面右侧下载列表,Safetensors 格式,workflow 在 Trainning data 压缩包内
The download list on the right side of this page is in Safetensors format, and the workflow is included in the Training data compressed file. The example images and videos also include workflows (yes, you can directly throw the original video files into ComfyUI and try to capture the workflow)
[ The adaptability test results of WAN1.2 LoRAs for VACE show that about 75% of I2V/T2V LoRA weights can take effect, but the sensitivity is reduced ( try to increase the LoRA weight ,more than 100% Sometimes it can be helpful ) ]
Fullview of Aiwood WAN-ACE Fully functional workflow:
📌 Wan2.1-VACE provides solutions for various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing creators to freely combine these capabilities to achieve complex tasks.
👉 Multimodal inputs enhancing the controllability of video generation.
👉 Unified single model for consistent solutions across tasks.
👉 Free combination of capabilities unlocking deeper creative
WAN实时生成来了!Hybrid AI model crafts smooth, high-quality videos in seconds
The CausVid generative AI tool uses a diffusion model to teach an autoregressive (frame-by-frame) system to rapidly produce stable, high-resolution videos.
In this repository, we present Wan2.1, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.
ON-THE-FLY 实时生成!Wan-AI 万相/ Wan2.1 Video Model (multi-specs) - CausVid&Comfy&Kijai - workflow included
In this repository, we present Wan2.1, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.
License Scope
Creative License Scope
Online Image Generation
Merge
Allow Downloads
Commercial License Scope
Sale or Commercial Use of Generated Images
Resale of Models or Their Sale After Merging
Download SeaArt App
Continue your AI creation journey on mobile devices


 CausVid 加速器
CausVid 加速器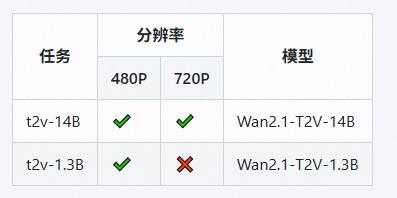

 LightX2V: Light Video Generation Inference Framework
LightX2V: Light Video Generation Inference Framework


